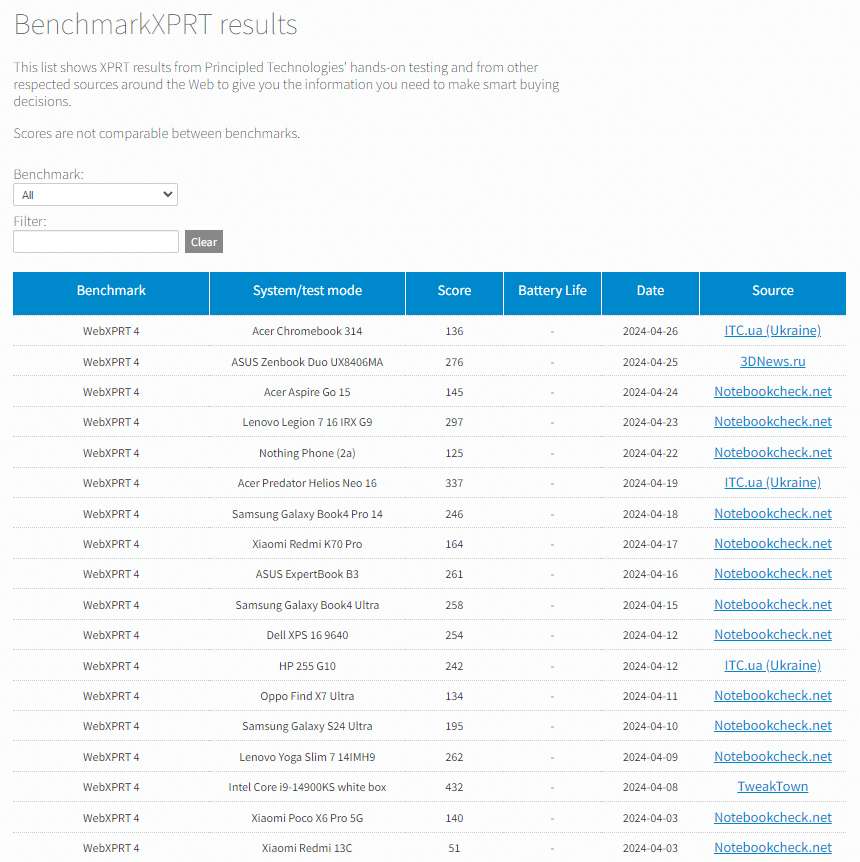
Some of our readers have been following the XPRTs since the early days, and they may remember using legacy versions of benchmarks such as HDXPRT 2014 or WebXPRT 2013. For many years, whenever we released a new version of a benchmark, we would maintain a link to the previous version on the benchmark’s main page. However, as interest in the older versions understandably waned and we stopped formally supporting them, many of those legacy XPRTs stopped working on the latest versions of the operating systems or browsers that we designed them to test. While we wanted to continue to provide a way for users to access those legacy XPRTs, we also wanted to avoid potential confusion for new users who might see links to old versions on our site. We decided that the best solution was to archive older tests in a separate section of the site—the XPRT archive.
Recently, as we discussed XPRT plans for 2025, it became clear that we needed to add AIXPRT and CloudXPRT to the archive. Both benchmarks represent landmark efforts toward our ongoing goal of providing cutting-edge performance assessment tools, but even though a few tech press publications and OEM labs experimented with them, neither benchmark gained enough widespread adoption to justify their continued support. As a result, we decided to focus our resources elsewhere and halt development on both benchmarks. Since then, ongoing updates to their respective software components and target platforms have rendered them largely unusable. By archiving both benchmarks, we hope to avoid any future confusion for visitors who may otherwise try to use them.
Over the coming weeks, we’ll be moving the AIXPRT and CloudXPRT installation packages to the XPRT archive page. We’re grateful to everyone who has used AIXPRT and CloudXPRT in the past, and we apologize for any inconvenience this change may cause.
If you have any questions or concerns about access to either of these benchmarks—or about anything else related to the XPRTs, please let us know!
Justin