
Enterprises increasingly rely on computationally demanding machine learning (ML) workloads. As ML becomes an indispensable tool for innovation, many IT professionals face the challenge of figuring out how to utilize datacenter infrastructure in a way that provides the flexibility and scalability they need to compete, without sacrificing the performance they need to lead the way.
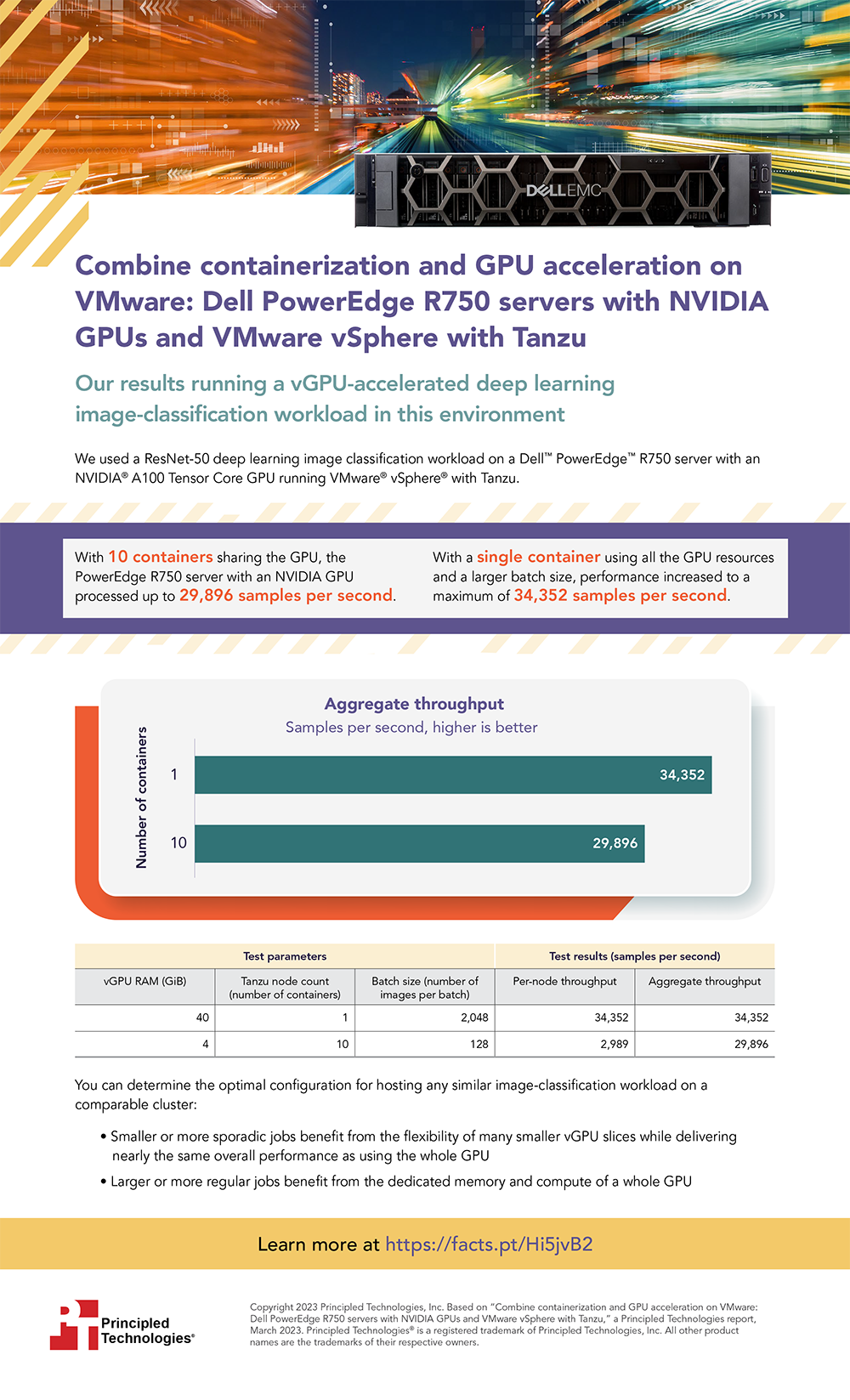
IT admins can meet this challenge head on by combining containerization and GPU acceleration in virtualized environments, allowing them to optimize configurations. We recently demonstrated the effectiveness of this approach by measuring ResNet-50 deep learning throughput on a Dell PowerEdge R750 with a single NVIDIA A100 Tensor Core GPU supporting a VMware vSphere with Tanzu containerized environment. When using GPU virtualization to allow 10 containers to share the single GPU, our solution achieved throughput of 29,896 samples per second. With a single container using all the GPU resources and a larger batch size, the solution achieved throughput of 34,352 samples per second. These results show that the PowerEdge R750 with an NVIDIA A100 Tensor Core GPU in a VMware vSphere with Tanzu environment can provide the flexibility that admins need to efficiently share their GPU compute capability and find optimal machine learning performance.
To learn more about our tests, check out the report and infographic below.



Principled Technologies is more than a name: Those two words power all we do. Our principles are our north star, determining the way we work with you, treat our staff, and run our business. And in every area, technologies drive our business, inspire us to innovate, and remind us that new approaches are always possible.



